TensorRT-LLM
Overview
Jan uses TensorRT-LLM as an optional engine for faster inference on NVIDIA GPUs. This engine uses Cortex-TensorRT-LLM (opens in a new tab), which includes an efficient C++ server that executes the TRT-LLM C++ runtime (opens in a new tab) natively. It also includes features and performance improvements like OpenAI compatibility, tokenizer improvements, and queues.
TensorRT-LLM engine is only available for Windows users, Linux support is coming soon!
Requirements
- NVIDIA GPU with Compute Capability 7.0 or higher (RTX 20xx series and above)
- Minimum 8GB VRAM (16GB+ recommended for larger models)
- Updated NVIDIA drivers
- CUDA Toolkit 11.8 or newer
For detailed setup guide, please visit Windows.
Enable TensorRT-LLM
Step 1: Install Additional Dependencies
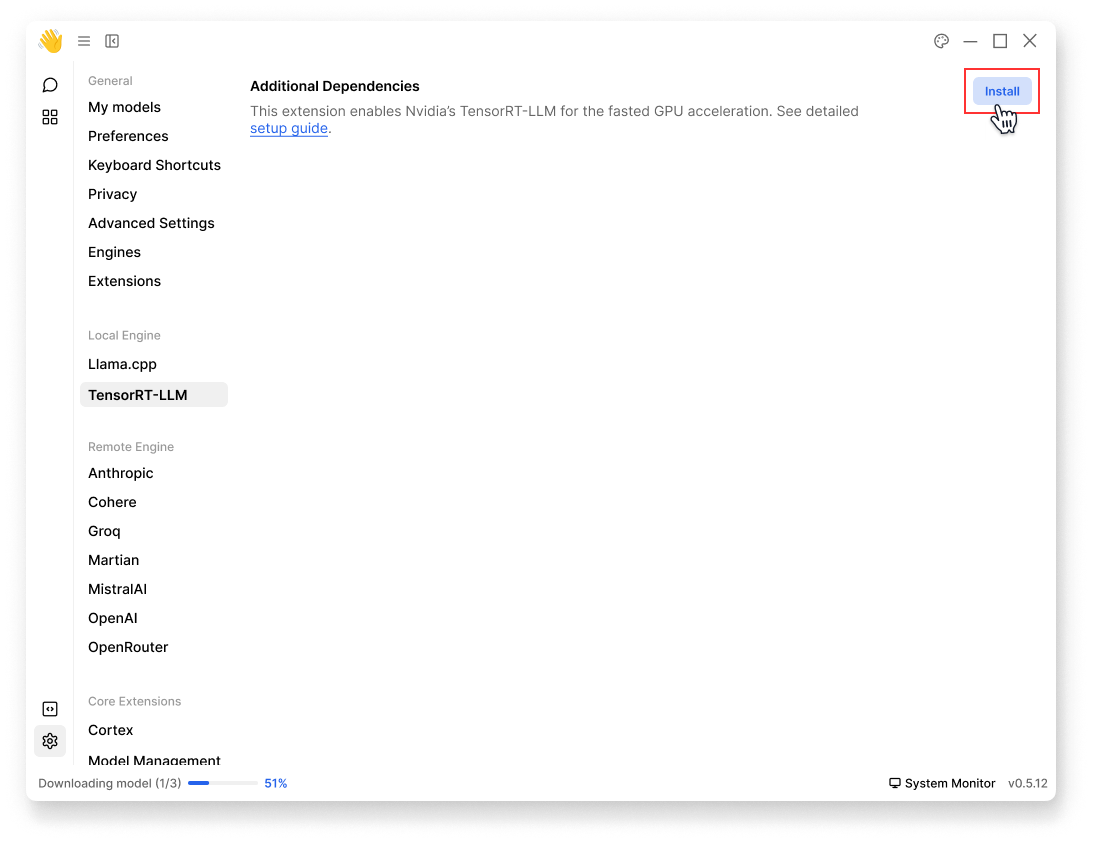
- Navigate to Settings () > Local Engine > TensorRT-LLM:
- At Additional Dependencies, click Install
- Verify that files are correctly downloaded:
ls ~/jan/data/extensions/@janhq/tensorrt-llm-extension/dist/bin# Your Extension Folder should now include `cortex.exe`, among other artifacts needed to run TRT-LLM
- Restart Jan
Step 2: Download Compatible Models
TensorRT-LLM can only run models in TensorRT format. These models, also known as "TensorRT Engines", are prebuilt specifically for each operating system and GPU architecture.
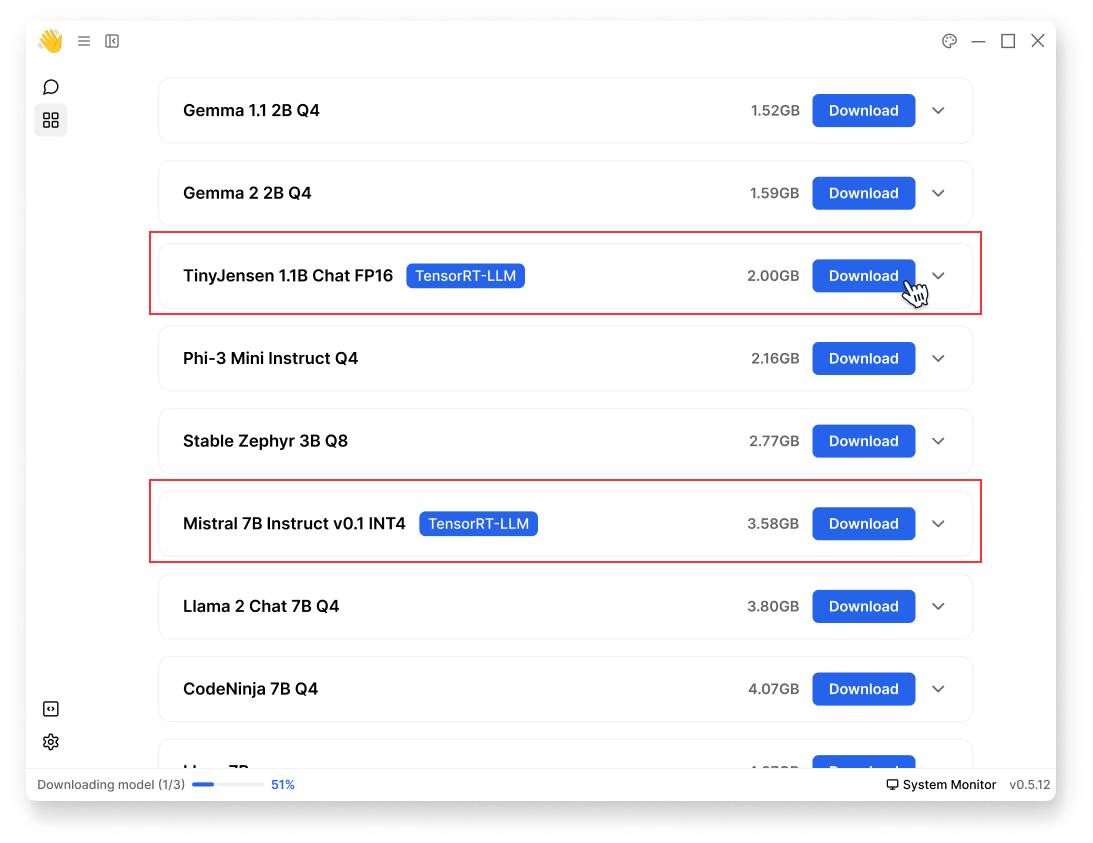
We currently offer a selection of precompiled models optimized for NVIDIA Ampere and Ada GPUs that you can use right away:
- Go to Hub
- Look for models with the
TensorRT-LLMlabel & make sure they're within your hardware compatibility - Click Download
This download might take some time as TensorRT models are typically large files.
Step 3: Start Threads
Once the model(s) is downloaded, start using it in Threads